Multi-user/Multi-tenancy
It’s not uncommon for a single individual to access a SaaS-based system within the context of different companies. For example, someone using their own company’s CRM system plus one of their business partner’s. Another example would be a contractor logging into multiple client systems.
Yet another one would be a reseller accessing the systems of multiple suppliers. We can call this “multi-user/multi-tenancy”.
One way to deal with this is to simply ignore it. Allow/force users to create new loginids to access different company systems. The issue here though, is that in an environment where access may be sporadic, users may quickly forget these additional loginids.
A related issue is in enforcing uniqueness of loginid. Many SaaS systems require an email address to be used. This has several benefits:
- It is guaranteed unique
- It provides an additional “secure” channel of communication for automated password resets etc.
- It won’t be forgotten by the user
However, in this case of requiring different loginids per company system, then login to multiple companies would require multiple email addresses – not a practical solution.
A better approach from the user perspective is to maintain the email address model for loginid, but provide the user the option to access whichever companies they are authorized to do. This can happen prior to login, for example, via connecting to a unique url such as:
- www.SaaSprovider.com/companyA
- www.SaaSprovider.com/companyB
- etc..
..although this does require memorization and prior knowledge of the URL’s. A more user friendly approach is to provide a list of available companies for the identified user to access:
www.SaaSprovider.com
Hello john.doe@self.com, please choose a company to connect to:
- Company A
- Company B
Data Partitioning
Another important point for multi-tenancy is data partitioning. This is made complex because of the competing drivers of security, scalability and manageability:
- Security – More rigid separation between company data sets
- Scalability – Configurable separation between company sets based on usage
- Manageability – “Gross-up” company data sets to ease backup processes etc
The right solution is dependent on the specifics of the system in question. For example, a system holding board materials for customers would require strict separation, not just in the live system, but continuing through to backups too. This is to cover the case of subpoenas that should only affect the named company and not other companies in the same back-up group. Since scalability requirements for board portals are light, this is an easy trade-off to make. Other systems, such as CRM would place a greater premium on scalability and manageability, and suggest a different solution.
Another factor is server location. European customers will get faster response times from a European based server. Likewise for US-based and Asia-Pacific based customers. This approach makes such geo-balancing straightforward.
Ideally, the architecture should support a range of positions, since a vendor’s customers will vary in both sensitivity to such matters (“we demand in-country hosting”) and size (“and we’re happy to pay for it”). SalesForce may be best known for it’s SME customers, and they have a special pricing package for up to 5 users, but they also have Japan Post as a customer with 50,000+ users. Clearly, one size won’t fit all for many B2B SaaS vendors.
Finally, any architecture, in an ideal world, should use replaceable vendor systems. This is to avoid lock-in to any one vendor. Of course, like all rules, this one is meant to be broken when there is sufficient benefit and minimal risk. The point is that such a determination should be recognized and considered as part of the design process, not something that just ‘happens’.
User Router Architecture
One architecture that addresses both the needs for flexible data partitioning, as well as multi-user/multi-tenancy, is what we can call User Router Architecture. In this model there is one single logical datastore for users, with one single logical datastore per client company. The user may have access to one or many of these logical datastores. By maintaining a logical layer separation, these individual client company datastores can be mapped onto actual physical databases as required, taking into account the security, scalability, and manageability issues introduced previously.
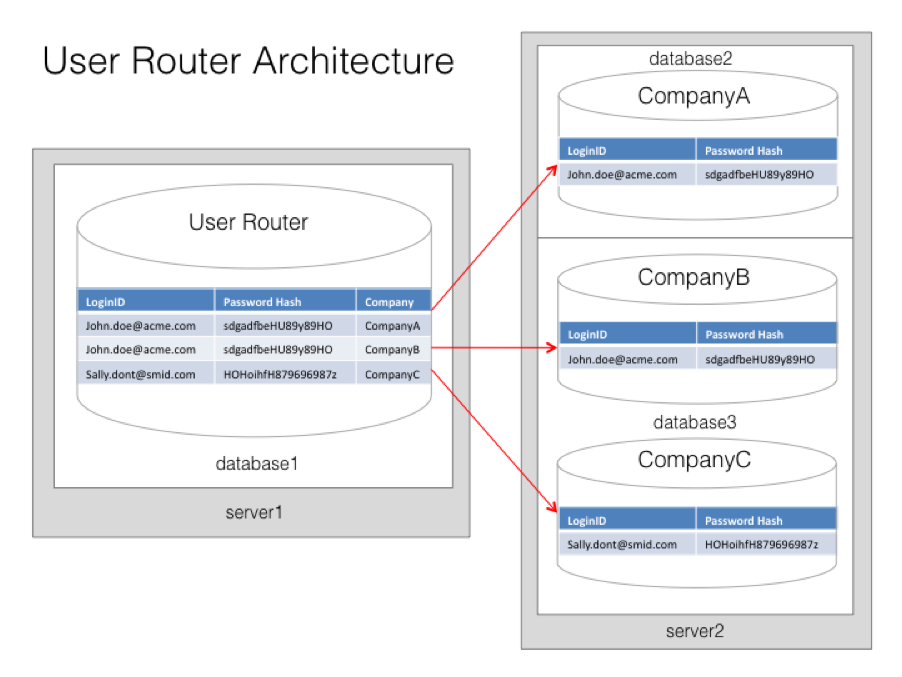
These individual databases can then be mapped onto the appropriate physical hardware.
Inside each database we may have multiple company data sets. Keeping these separate and avoiding any possibility of cross-contamination is critical. One technique is to attach every data record with a companyid field and make this compulsory as part of any access method. This does, of course, open up the possibility of programmatic errors allowing cross-contamination. An additional technique (i.e. it should not be thought of as exclusive) is to use database functionality (if available) to separate each customer into individual schemas. This provides a centrally managed point of security by providing “a database within a database”.
It’s still worth enforcing the maintenance of companyid with every data element, as this enables a scalable distributed GUID to be constructed – simply concatentating companyid with objectid according to some token scheme, will give you a logical GUID, which can be supplemented by location information if the GUID has to be instance unique to support replication, for example. A logical GUID alone will still provide URL addressability. Note that how such a GUID is encoded for user presentation as part of the URL can be separate from how it’s internally managed.
Access & Security
Logging In
As part of the idealized login process a user would simply login as per normal from the SaaS Provider website. This login process would be queried directly against the user router. On success, the user would be presented with a list of available companies to continue on to. On selection the user would be passed through to the specific company database. This could be done directly, but it may be better to revalidate the user against the same user/password-hash record stored in the company datastore. Whilst somewhat redundant in this picture, it does enable the company datastore to be accessed independently (perhaps directly via URL) if required. In the event that a user has only one company available (note for many SaaS providers, this will be the majority), the redirection is essentially invisible. Whilst there is an increase in latency, it’s unlikely anyone will care about a log in process taking 3s rather than 2s, and the latency is likely to be much less in practice. Also, the routing information could be stored locally in a cookie as part of the ‘remember me’ functionality. Updating the authorized companies in this event would raise a login error on attempted login that could then rewrite the locally stored routing information as appropriate.
Managing Credentials
Since the credentials are stored in each datastore the user has access to, each company datastore administrator can revoke these/add these at will. The system will need to write to both the company datastore as well as the user router. There is the potential for one write to fail, but such an event is “fail-safe” in the literal sense that failure would be safe. Since the user needs to pass access to both systems (user router and company), then only one has to be revoked to disable access. Since adding new users is an infrequent operation, the additional latency is unlikely to be important.
A more complex change is managing passwords. When a password is updated, not just the company datastore of immediate interest and user router have to be updated, but all the other accessible company datastores too. The potential for write failures is increased, but this can be mitigated by forcing a guaranteed write protocol (which could also be used in the above case of adding/deleting users). This would increase user response time, but since password changing is typically once every few months (if that!), then this is unlikely to cause issues. Another approach could be to allow different passwords per company. This requires careful consideration. Practically speaking, adding passwords to people’s memory usually involves them being written down. Or forgotten. Also, such an approach would require there to be no password on the initial routing request (or perversely adding yet another password to be remembered forgotten), and allow anyone armed with a userid to see which companies are available to them, creating a potential security weakness.
However, yet another factor to be considered is password policy. It’s not uncommon for SaaS Providers to enable their clients to enforce custom password policies. It would be awkward if a user changed their password on CompanyA to something that was invalid on CompanyB. Clearly one could enforce a “strictest” applicable policy of all companies accessible, but this is now starting to look like a mini-application in itself. Also the case of adding access to a new company whose password policy is incompatible with your existing password would need to be managed too. Worse, it may even be possible for companies to enforce incompatible policies (CompanyA: “must have at least one special character”, CompanyB: “must not contain any special characters”), preventing any single password from being acceptable.
This objection depends upon the importance of allowing independent company password policies, a factor which is market dependent, being more common amongst the larger enterprises with dedicated IT staff to decide such things. Smaller customers will likely not care, as witnessed by the increasing number of SaaS-based systems accepting third party authentication such as OAuth, which means the third party password policy is implicitly accepted.
Benefits
For many SaaS systems, this may be as much scalability as is required. Potentially every customer could be on a separate machine, if capacity demanded it. Only when an individual customer exceeded the performance available from a single machine, would it be necessary to look at techniques such as clustering and sharding, almost all of which are technology specific.
The architecture supports the two extremes of all customers in a single database, to one customer per database, and all points in between. Dialing in the right balance is a function of customer requirements, scaling, and marketing priorities. For many SaaS providers starting out, all of these are essentially unknowns.
The user router datastore represents a single logical instance, but the data (new users, password changes, and newly granted access to companies) is update light. Reads only occur at log-in. With these parameters, even modest hardware and software can support datastores of millions of rows with ease. B2B SaaS providers are unlikely to more than 10 million individual users (and if they do, they have a nice problem, as well as the budget to attack systems software scalability).
Since the User Router datastore is update light, it’s relatively easy to arrange master/slave replication to support scaling and redundancy. Latency is unlikely to be an issue, since the impact would be to delay someone logging in for the period of that latency (which should still not be more than single seconds), most likely unnoticed, and a benign inconvenience at worst.
Individual company datastores can exceed the abilities of a single physical instance, but for most SaaS providers, such customers are corner cases (and highly desireable!). The fact is a model that required separate hardware per customer is really no longer SaaS from an economic perspective and is more like the ASP (Application Service Provider) model of old.
The architecture supports either pre-selection (e.g. custom urls), or post-selection (e.g. login choices).
The architecture is logically independent of anything done at the systems software level to scale datastores. It doesn’t depend on any specific vendor functionality and can be used with any type of database – SQL, noSQL, columnar, document, graph, etc. At worst case, it becomes an unnecessary operations overhead, but it doesn’t detract or prevent any other scaling exercises.
A simple extension to the user router also allows alternate codebases to be used. Whilst the aim of every SaaS vendor is to maintain a single codebase (albeit with configuration capability per customer), it’s often useful to enable alternate codebases to stage introduction of new versions which may be radically different (e.g. when the system is re-architected every 5 years), and may wish to phase the introduction to customers.
Weaknesses
Implementing such an architecture takes additional work at the start over just putting everyone in the same datastore and using the vendor database capabilities for scaling when the need arises. The cost needs to be evaluated in terms of how it affects time-to-market, how useful it is, and how much (more) it would cost to implement later, rather than from the outset.
The benefits touted above may be inapplicable. There may be no practical need for a user to join more than one system, and there may be no marketing (i.e. perceived security), security (i.e. actual security) or legal concerns on data separation.
Summary
Multi-user/multi-tenancy may not be initially seen as an important requirement, but it’s a very attractive one from the SaaS Provider’s marketing perspective, since it enables a potential viral channel for adoption. Many B2B companies have partners involved in some way, and being able to give them access to their own SaaS systems benefits not just the customer, but also the SaaS Provider too.
The User Router Architecture provides a considerable degree of flexibility in exchange for an additional burden in implementation and issues around multi-system password management, although no more than would be found in using external authentication such as Google single sign-on.
Ultimately, all architectures are best seen as insurance policies – an upfront, affordable investment, in order to mitigate future uncertain, potentially crippling, costs. The best architecture is the one that delivers the most cover for the least premium. Choice of architecture is ultimately one of estimating risk, and different systems clearly have different profiles.
